

こんにちは、おかちゃんせんせいです!
今回は特にアクセスが多い記事に関連する記事について、
ブログで共有したいと思います。
テーマは
GASを利用したWebスクレイピング
です。
目次
Webスクレイピングする上での注意事項
特にアクセスが多いのが、VBAを用いたスクレイピングに関する記事です。
 【業務効率化】Windows版Excel VBAでChromeを自動操作して、Webスクレイピングする方法(初期設定編)
【業務効率化】Windows版Excel VBAでChromeを自動操作して、Webスクレイピングする方法(初期設定編)
スクレイピングとは、分析目的でWeb上からデータを収集する手法のこと。
VBAだけではなく、RPAでもスクレイピングは可能ではありますが、どんなサイトでもスクレイピングをしていいわけではありません。
利用規約として、明示的に禁止しているサイトも中にはあるため、スクレイピングするためには、最低でも下記内容を確認しておくとよいでしょう。
・/robot.txt
・利用規約
・WebAPIの有無
スクレイピングする上での注意事項や禁止サイトに関する情報については、下記サイトが参考になると思います。
GASでのWebスクレイピングはGAS初心者にもお勧め
では、以上のことを踏まえて、GASでスクレイピングする方法について共有したいと思います。
なぜGASを今回ピックアップするのかというと、VBAと比べると懸念点が少なく、構造さえ的確に把握できれば、比較的容易に実装できると感じたからです。
VBAやPytonの場合、Seleniumを活用することになるケースが多いかと思いますが、ChromeとChromeDriverのバージョンを一致させないとエラーが出るのがとても厄介です。
もちろん自動的に更新するために、ChromeDriverManagerをインストールする方法もありますが、バージョンを上げたことで予期せぬ不具合に遭遇することもあります。
 【解決】Chromeのバージョン103にてExcel VBAでWebスクレイピングするときにエラーになる件(2022年7月5日時点)
【解決】Chromeのバージョン103にてExcel VBAでWebスクレイピングするときにエラーになる件(2022年7月5日時点)
そのため、個人的には管理する側の視点に立つと、予期せぬ不具合によるリスクはできる限り回避したいと考えています。
その点、GASの場合には、特にブラウザやWebDriverのバージョンを気にする必要がなく、ライブラリの追加だけでOKです。
しかも、ライブラリのメソッドを活用すれば、必要な情報を特定のURLから取得して、特定の項目だけを抽出することも容易でした。
ちなみに、GASでWebスクレイピングする際にとても参考になる情報は、下記リンク先です。

GASでWebスクレイピングするための準備
では、早速GASでWebスクレイピングをするための準備をしたいと思います。
まず、AppsScriptを起動します。
もし取得したデータをGoogleスプレッドシートに転記したい場合には、スプレッドシート上の「拡張機能」から「AppsScript」を起動します。
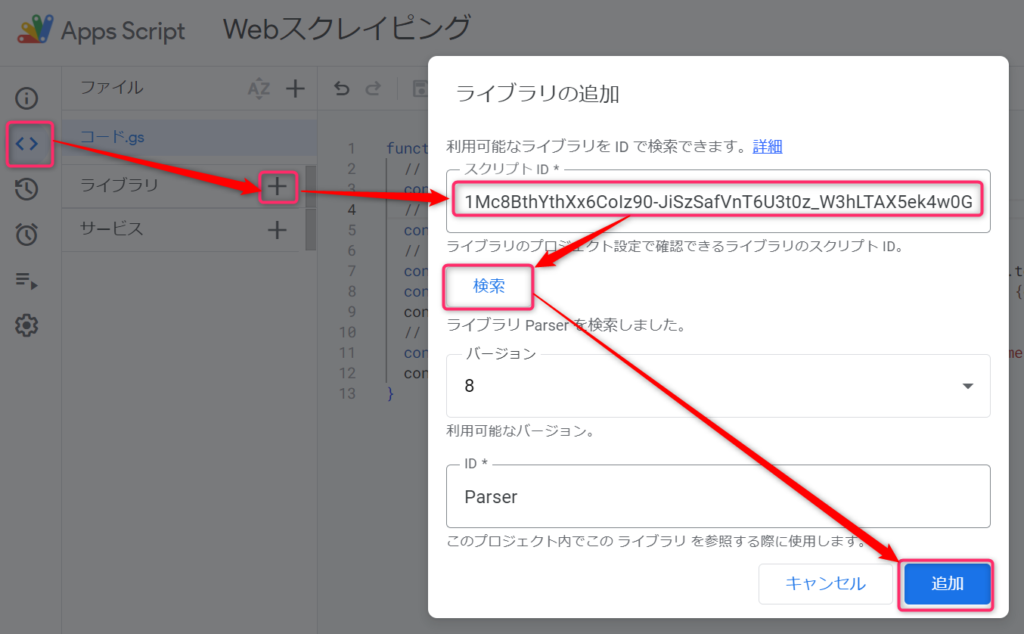
次に、エディタからParserライブラリを追加します。
追加する方法は簡単で、エディタの左側にライブラリがあります。
そのライブラリの右に+ボタンがあるのでクリックすると、ライブラリの追加ダイアログが表示されます。
ライブラリIDに下記IDを入力して『検索』をクリックします。
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
すると、バージョンとIDが表示されますが、今回はIDがParserになっていることを確認して『追加』をクリックします。
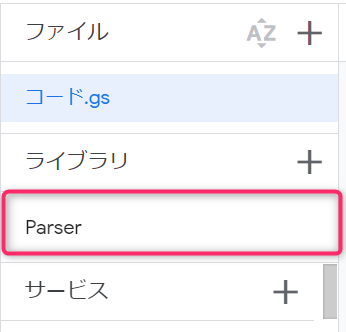
すると、ライブラリの欄に「Parser」が表示されれば、ライブラリの追加は完了です。
ライブラリはGASで標準で提供されていない独自のメソッドやプロパティを利用できる便利機能で、自分が用意したものだけでなく、他の人が用意したものについてもスクリプトIDがわかられば使えるようになります。
これで準備完了です!
サンプルコード
サンプルコードについては下記の通りになります。
function getRanking() {
// Step1:スクレイピングしたいサイトURLを設定する
const url = "https://qiita.com/";
// Step2:URLにGETリクエストを送信してレスポンスを文字列として取得する
const res = UrlFetchApp.fetch(url).getContentText("utf-8");
// Step3:条件に一致する最初の要素を取得する
const rankingTag = Parser.data(res).from('<p class="style-hdi3tu">').to('</p>').build();
const translatedText = LanguageApp.translate(rankingTag, 'en', 'ja', {contentType: 'text'});
console.log(translatedText);
// Step4:条件に一致する全ての要素を取得する
const ranking = Parser.data(res).from('<p class="tagRanking-screenName style-i9qys6">').to('</p>').iterate();
console.log(ranking);
}途中不要なコードもありますが、
Webで公開されている中から特定の情報を収集できます。
今回はQiitaのトップページからタグランキングを取得します。
const url = “https://qiita.com/”;
まず最初は、スクレイピングしたいWebページのURLを設定します。
const res = UrlFetchApp.fetch(url).getContentText(“utf-8”);
次に、指定したURLを送信してレスポンスを取得します。
さらに、getContentTexT()メソッドを用いて、文字列として取得します。
変数resには、ページ全体のHTMLコードが文字列として格納されます。
const rankingTag = Parser.data(res).from(‘<p class=”style-hdi3tu”>’).to(‘</p>’).build();
const translatedText = LanguageApp.translate(rankingTag, ‘en’, ‘ja’, {contentType: ‘text’});
console.log(translatedText);
次に、タグランキングのタイトルを取得します。
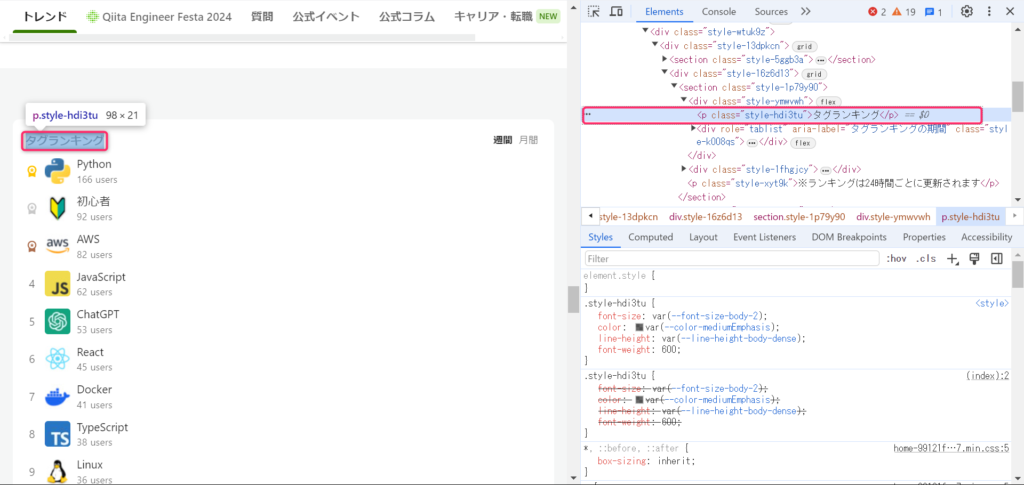
タグランキングを表示しているコードを確認するためには、Chromeの場合には調べたい対象にカーソルを当てて、右クリック。
一番下にある「検証」をクリックすると、右側に検証ツールが表示されます。

ツールを確認すると、「タグランキング」という文字列は<p class=”style-hdi3tu”>と</p>の間にあることがわかります。
そこで、
Parser.data(res).from(‘<p class=”style-hdi3tu”>’).to(‘</p>’).build()
とすることで、fromとtoの間にある文字列を取得できます。
buildメソッドは条件に一致する最初の要素を取得できる
(補足)
LanguageApp.translate(rankingTag, ‘en’, ‘ja’, {contentType: ‘text’})は、英語を日本語に変換します。
const ranking = Parser.data(res).from(‘<p class=”tagRanking-screenName style-i9qys6″>’).to(‘</p>’).iterate();
console.log(ranking);
最後は、条件に一致する全ての要素を取得します。
今回はタグランキング欄に表示されている10つの要素(文字列)を取得するために、Step3と同様でどんなタグ(文字列)に囲まれているかを再び検証ツールで確認します。
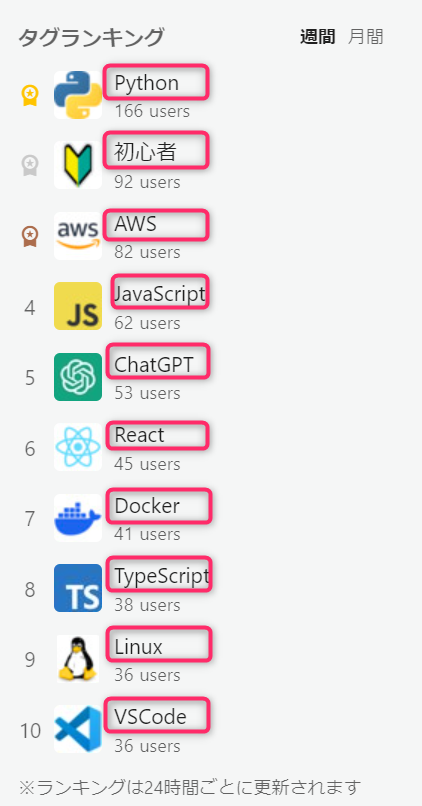
調べてみてわかるのは、下図のような法則性です。
<p class=”tagRanking-screenName style-i9qys6″>●●●</p>
そこで、
Parser.data(res).from(‘<p class=”tagRanking-screenName style-i9qys6″>’).to(‘</p>’).iterate()
とすることで、fromとtoの間にある文字列をすべて取得できます。
iterateメソッドは条件に一致する全ての要素を取得する

- Webスクレイピング可能なページかどうかを調べておく。
- 検証ツールで取得したい文字列はどのようなタグ(文字列)で囲われているかを確認する。
- 条件に一致する最初の要素だけを取得する場合にはbuildメソッド、すべて取得する場合にはiterateメソッドを使用する。
↓ 今日も1日ポチッと ↓
↑ いつもボタンクリ応援・口コミ応援ありがとうございます ↑

